Whenever you get a bunch of technical architects in a room with a whiteboard and markers, it’s not going to be long before somebody goes up to the board and draws a box. Doesn’t matter the kind of architect: solution, application, infrastructure, enterprise, and, yes, data. We love whiteboards. We love whiteboards with boxes and lines on them even more. Have you ever been in an architecture meeting where a small, informal betting pool emerges wagering how long it will be before someone draws a box on the board? I have. More than once.
After some drawing and discussion and erasing and some more drawing and discussion you have a whole bunch of boxes and lines. A solution! Hopefully. The next step is to clean up the diagram and draft it in Visio or PowerPoint. In most projects this is the “moment of maximum orderliness.”
It’s so neat and uniform. We architects like neat and uniform. At least most of us do.
And then the real world happens.
It has been said that, “a PowerPoint slide never abended.” (If you’ve never worked on a mainframe or worked with someone who worked on a mainframe, you might need to look that up.) The point is that it’s easy to draw something on paper when you don’t have to deal with the real-world situations that arise when you actually try to implement the thing.
I would be willing to bet that most everyone reading this article has drawn a traditional analytics architecture diagram. Most of the rest have seen one. For anyone left over, here’s what a very basic one looks like.
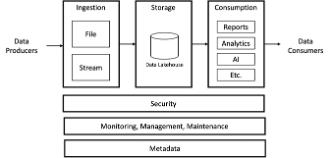
Ingestion on the left, storage in the middle, and consumption on the right. Security, monitoring, management, maintenance, and metadata usually appear below. The enterprise analytics team has a standard ingestion methodology. Maybe one path for files and another for transactions, a data lakehouse in the middle, and a standard toolset for consumption.
Nice neat big boxes. Beautiful. You can almost see the data flowing through it. That probably describes a large part of your analytical ecosystem.
Architecture diagrams are best expressed in the Peanuts comic strip from July 29, 1959. Snoopy famously loves butterflies, and is watching one as it flies by and lands on a nearby bush. He leans over and puts his nose up close but then walks off dejectedly thinking, “He was a lot better looking from a distance.”
Architecture diagrams are a lot better looking from a distance.
When we look at the big boxes more closely, we discover that they’re not as neat and tidy as we thought or we’d like. This is especially true when representing the current state of an existing environment, perhaps in preparation for a cloud migration or modernization.
Most analytics environments have a set of dominant patterns. This is really what the diagram is illustrating. The enterprise standard file and transaction ingestion processes. Zoom in and we discover a smorgasbord of additional approaches. Source system files are loaded manually. Data in one database is transferred directly into another. A few source systems use a different ETL tool, and others use yet another different ETL tool. One group built their own process for their own warehouse, and continued to use that same process following its integration into the enterprise environment. Each is a different load process. Each is managed by a different team.
These are the OTHERWISE and the ELSE.
These are the ones that aren’t nicely enumerated in the SWITCH or CASE or IF. Instead of one or two boxes labeled “Ingestion,” you may really have dozens. They don’t fit into our nice neat diagrams. So, we just ignore them. Maybe that’s not WHY we ignore them, but it’s certainly easier to put them out of mind when they’re out of sight. After all, they’re working just fine as they are. No need to upset the applecart.
I recently published several articles warning about the pitfalls of migrations and consolidations (Look Before You Leap – Analytical Data Consolidation Edition, The Hidden Costs of Migration Part 1, and Part 2). It would be reasonable to assume that my advice here would be to let well enough alone and focus on delivering new business value. Business value is a good thing, but recall that I also said that the decision to move forward with a migration or consolidation should be based on a cost/benefit analysis of ALL of the factors.
Let’s look at a couple ingestion-side factors.
Resources: The dominant ingestion pattern typically supports thousands or even tens of thousands of data feeds, and is usually managed and maintained by a small team. On the other hand, each one-off may itself require a small team. A much less advantageous ratio. No company I know has a surplus of data and analytics people. When designed and implemented properly with the appropriate implementation flexibility, the integration of these one-off feeds can be completed relatively quickly, with no impact to the user community, and with minimal impact to the development teams. The small teams that used to support the one-off feeds can be redirected toward improving the user experience or creating data products or delivering business value or collecting metadata or refining processes or enhancing the applications.
Downstream Process Support: The primary purpose for capturing and storing load process information is to keep track of load process status. Obviously. But sometimes that information is used for other purposes, including user support applications. Those applications need to gather information from the one-off processes separately, and as a result they’re often not included.
Metadata Collection: The key to a federated implementation architecture is centralized metadata. In the best case, the metadata for the one-off loads is captured in the central repository. Odds are, though, it isn’t. And just harvesting table and field names into the repository isn’t enough. Definition and expected content are required at minimum. Imagine searching for customer account number and seeing two dozen cust_acct_nbr fields returned. Now, decide which one to use when the only other available information is the table name.
The same is true on the consumption side. I’ve long said that, “if you can buy it or download it, someone is using it.” I’ve also said that consolidation and migration for its own sake is a fool’s errand. Users have their own tool preferences, and those tools are often tailored for their business questions and business processes. That said, cost/benefit and business process implementation analyses may uncover opportunities for optimization. For example, if you’re using a super-powerful (and expensive) analytical package just to prepare data and run queries, you might be able to accomplish the same thing much less expensively and with minimal disruption.
My point is that we architects tend to ignore the outliers. They don’t fit into our nice tidy boxes and clutter up our diagrams.
Instead of ignoring the one-offs, we need to focus on them.
It might seem easier to just continue loading data manually. After all, it’s just one person and it takes just a few minutes each day. But those few minutes each day add up. They also require a knowledgeable backup to take over when they’re unavailable. Now multiply that by all of the non-standard feeds.
When documenting an existing environment, it’s critical to ferret them out.
Sometimes they’re not easy to find, having flown under the radar for years. But when preparing for a migration or modernization you’ll invariably discover that these one-off processes will unexpectedly consume a disproportionate amount of effort, time, and attention. Everything looked good to go and then you get an angry email.
Look for opportunities to incrementally bring them into the fold. Do the cost/benefit analysis. In these cases, you’ll often find that everyone benefits.


