An AI made a decision. You want to know why it decided the way it did. Seems reasonable.
Well, reasonable depending upon the AI technique being used. Some are more transparent than others.
First, we need to know what we’re asking for: interpretability or explainability. Both seek to understand the functioning of a decision system, but they differ substantially in what they’re looking at.
Interpretability is understanding the decision-making process of the AI model within the model itself, while explainability is describing the decision as well as the decision-making process to a person.
Decision trees, rule-based systems, and fuzzy logic systems are generally interpretable. You can trace the path through the decision tree, and see the IF-THEN relationships between inputs and outputs in a rule-based or fuzzy logic system.
Random forests and deep neural networks, on the other hand, are not interpretable. Especially deep neural networks. Especially the stuff of which Generative AI are made.
These networks can be explainable, though. Post hoc analysis of the model through feature attribution (e.g. SHAP) and counterfactual-based techniques can provide insight into the inputs that most strongly influence the output. But they still treat the network itself as a black box. You could put a neural network on top of a neural network to correlate regions of activation to try to extract the most relevant features. It’s sort of like poking at a part of a brain to see what happens. But you’re still not getting down to the “neural” level.
The search for automated intelligence is not new. The key theme of my doctoral research was to develop a methodology for training an expert system without employing an expert. Self-organizing and self-learning systems weren’t new at the time either. But I wanted to be able to examine the rules to determine how each contributed to the final decision.
The approach used genetic algorithms to evolve rule-based fuzzy logic controllers. Once a controller successfully solved the problem, I could go back and look at the rules to see how the task was accomplished.
Sometimes the explanations were unexpected and, frankly, unsatisfying.
The solutions developed by these systems weren’t always straightforward. Or optimal. Or the way that a human expert would solve the problem. Here’s an example
The simplest physical simulation I used in my research was the cart-pole problem. The idea is to balance a pole vertically on top of a cart on a horizontal track before hitting either end. It’s kind of like balancing a baseball bat in the palm of your hand.
The controller is given the distance of the cart from the center of the track (x), the angular deviation of the pole from vertical (θ), the velocity of the cart (x ̇), and the angular velocity of the pole (θ ̇). The result is the force (F) to be applied to the cart.
Here’s an example of one of the evolved fuzzy logic rule bases that successfully solved the problem. The variables on the horizontal axes are all normalized from -1 to +1, the fitness on the vertical axes range from 0 to 1. The width of the triangle represents the range of that variable’s applicability. When there isn’t a triangle, the system determined that the variable was not applicable to that rule.
For example, the first rule ignores the x position of the cart as well as the pole angle. When the cart is moving to the right but the pole is falling to the left, the cart should be pushed to the left, reversing that leftward fall.
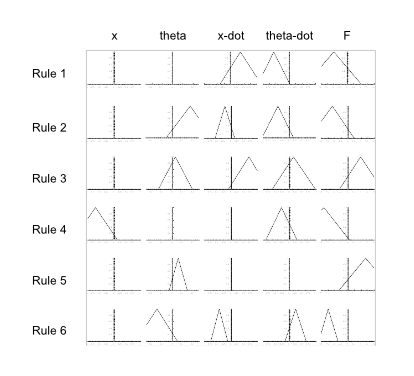
The second rule also ignores the x position of the cart, but when the pole is pretty far to the right but moving to the left, and the cart is moving to the left, the cart should be pushed to the left. The other rules can be interpreted similarly.
It probably does not look like what you expected. It certainly wasn’t what I expected.
This set of six rules successfully balanced the pole for more than 24 hours of simulated time starting in all of the training configurations, as well as several novel configurations not included in its training set. In this example, it brought the system nearly to rest in under 8 seconds. (Note: Since the physical system is inherently unstable, the controller never actually brings the cart and pole fully to rest, but rather establishes a slight oscillation.) Here’s a trace of each of the variables:
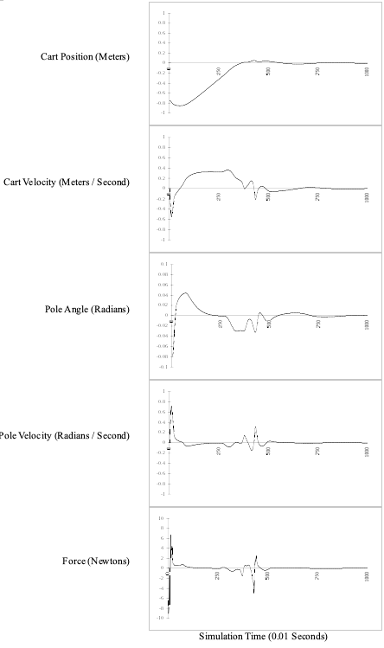
A lot of gross control at the very beginning, a hiccup in the middle, then stabilized. But how does it actually work?
A fuzzy logic rule base is interpretable because it is possible to trace each of the variables, see which rules are triggered, and determine the extent to which each contributes to the final output.
The key, though, is that it’s not the rules individually that matter, but rather in aggregate. In most instances, multiple rules are applicable to a particular configuration.
In some cases, a rule can be triggered even when the antecedent appears not to be satisfied. Look at the x ̇ variable in the first rule. We read it as “if the cart is moving to the right,” but we see that the triangle passes through the center line meaning that the rule could still be triggered slightly when the cart is moving to the left. That’s how fuzzy logic works.
That’s swell, but it makes it hard to understand what’s happening. People work better with explanations. Looking at the rules, you can sort of tease out some rough rules that approach an explanation, like, “When the pole is nearly centered, push to the right, otherwise push to the left.”
Huh?
That doesn’t sound right. That’s because, again, the rules work in concert to control the system, not individually.
We want what we have in the baseball bat analogy. When you were a kid (or adult) playing this game, how did you solve the problem? As the bat fell, you moved your hand in the direction of the fall to bring it back to vertical. So, an explanation might be expected to be something like “move the cart in the direction of the fall with a force roughly proportional to the deflection and the angular velocity of the fall.”
That’s not what we get here. We can observe and describe the behavior of the system, but that takes us out of interpretability and into explainability.
I can hear you thinking, “You sure took the long way around with that one.” Why spend so much time going into so much detail?
Because that was the easy one.
You see, interpretability isn’t always clean like a decision tree or wrapped up with a nice chain of cause and effect like the reveal on CSI or House M.D. You can’t trace through a neural network like a decision tree. There aren’t any rules. You can work your way through the calculation, I suppose. The numbers are all there. Maybe someone could unravel the millions of inputs and trillions of parameters to produce an F(x)-like function for each output. Research is ongoing, but I’m not sure how useful that calculation would be, especially in isolation.
We want the generative power of a neural network but the interpretability of a decision tree.
That’s understandable. Generative AI is working its way into seemingly every aspect of modern life. Think credit scoring and healthcare underwriting. And trust is a big problem.
Opacity undermines trust, and there’s not much that’s more opaque than a deep neural network.
You got the decision. You still want to know why.
Governments are starting to get involved. GDPR requires that all automated decision-making systems be explainable and interpretable. (Although I’m not sure how attainable that will be in practice. Especially the interpretable part.)
You can ask ChatGPT for the justification for a decision. It will probably give you a rational-sounding explanation. Is it correct?
You can use techniques like LIME (Local Interpretable Model-Agnostic Explanations) and SHAP (Shapley Additive Explanations) to help reveal which features in the data are most influential in the model’s decision-making process. Would you consider that to be either an interpretation or explanation? What do you do with the information once you have it? Besides, most people will not have access to these tools. Should they?
You’ve heard me say it here before. Here it comes again:
Don’t take generative AI results at face value.
Understand how context influences the response. Exercise the model. Explore different inputs.
In the absence of generative AI interpretability, consumers should be able to request the results of model runs based on adjacent assumptions.
Would I have gotten the loan if I hadn’t carried a credit card balance those couple months? What would my life insurance premium be if I lost 30 pounds? Let it explain its logic to you.
It’s not totally opening up the black box, but being able to see the sensitivity of the decisions may be one way to increase confidence. And given the trajectory of Generative AI, that’s going to be both a challenge and a requirement.


