A popular perception of artificial intelligence comes from the Menacing Computer movie genre. Skynet becomes self-aware and seeks to exterminate humanity. HAL9000 kills Discovery’s crew when they plan to disconnect it. Joshua wants to play a game of Global Thermonuclear War. And we’re all trapped in the matrix.
Yes, there are reasons for concern, but these aren’t among them. At least not now.
But for now, understanding a little bit about the foundations of artificial intelligence, and neural networks in particular, will make them less scary. Instead of a horror show, think of them like a magic trick. One where you can know the secrets yet still marvel at the result. And considering what can be accomplished using neural networks it does seem like magic. You start with a bunch of random numbers for parameters, do some “training,” and the resulting application can produce both an academic essay about the Gettysburg Address and a pretty good recipe for peach cobbler. I did neural network research 35 years ago in graduate school. It amazed me then and it still amazes me today.
Let’s begin our peek behind the curtain by level-setting on some terminology.
Artificial Intelligence encompasses several subfields that collectively seek to use computers to imitate human sensory, learning, reasoning, and motor functions. Examples include computer vision, speech understanding, natural language processing, machine learning, expert systems, knowledge representation, robotics, and speech, image, and text generation. Neural networks, like those used in ChatGPT and other generative language systems, fall under the heading of machine learning.
Machine Learning uses data and algorithms to improve the prediction, classification, or clustering accuracy of an application. For example, a machine learning application could be trained to recommend a product offering to a particular customer based upon their purchase history. Another could be trained to identify defective machine parts before they are shipped. Several different types of algorithms can be used to implement a machine learning application, one of which is a neural network.
Neural Networks are inspired by the structure of the human brain where interconnected neurons communicate through electrical and chemical signals. This sounds complicated, but the fundamental concept is simple. The network receives an input, does some internal processing, and produces an output.
In other words, a neural network simply calculates its output as a function of its input: Output = f (Input)
We use functions like this every day. For instance, a function can be defined that calculates the 9.75% sales tax due on purchases in Memphis. That’s expressed as:
Memphis Sales Tax = f (Purchase Price)
We can generalize the function by adding the sales tax rate as another input:
Flat Sales Tax = f (Purchase Price, Tax Rate)
We’re still calculating the tax on the given Purchase Price, but now Tax Rate describes how the function behaves. Let’s call Purchase Price the input and Tax Rate a parameter. We can continue adding parameters that further generalize application behavior. For large purchases, local sales tax might only be charged up to a maximum amount while state sales tax is charged on the entire purchase. This scenario could be expressed like this:
Limited Local Sales Tax = f (Purchase Price, State Tax Rate, Local Tax Rate, Maximum Local Taxable Amount)
This is essentially the same thing that a neural network does. It’s just that the functions that modern neural networks calculate are much, much, much more complex and have many, many, many more parameters. Three parameters were used in this last example. To give you a sense of scale, ChatGPT 3.5 uses 175,000,000,000 parameters. More recent models have as many as a trillion. But at the end of the day, it’s still just a really, really, really, really big function.
OK, now with that as background, let’s see what a basic neural network looks like.
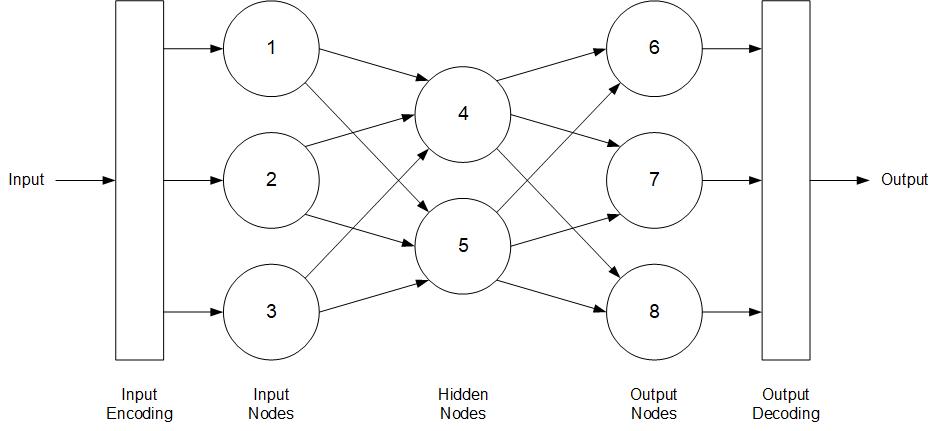
This is called … ready for it … a fully connected, feed-forward, three-layer neural network topology. Sounds impressive, but it’s really pretty straightforward.
Let’s start at the far left. The input could be an image or some text or a sound wave or a list of products or anything. But since computers can only operate on numbers, the first step is to encode the input into numeric form. There’s been a lot of really interesting recent research on encoding. But, again, encoding is just a function. The encoder takes some input, performs some calculation, and produces a numeric result. This result is passed to the Input Nodes.
The Input Nodes are fully connected to a set of Hidden Nodes, meaning that every Input Node sends the result that it calculates to every Hidden Node. Each connection has a weight associated with it which determines how much that Input Node contributes to the result of the function calculated by the Hidden Node.
Imagine you’re the Hidden Node labeled 4, and that the weight on the connection from Input Node 1 is large while the weight on the connection from Input Node 2 is small. The result that you calculate will be much more dependent upon the value coming from 1 than on the value coming from 2.
The same thing happens between each Hidden Node and each Output Node. The result is a three-layer network: Input Layer, Hidden Layer, and Output Layer. All these numbers flow across the connections from node to node, from the Input Layer to the Hidden Layer to the Output Layer. No connections back to a previous layer. This is referred to as a feed-forward network.
Sometimes the numeric result produced by the Output Nodes can be used directly. Sometimes we need to decode the result into something that can be more easily consumed like an image or some text or a sound wave or a product recommendation.
That’s it. Now you know how neural networks work. Just follow the connections.
Other common topologies are variations on those basic concepts. Deep Learning Networks have multiple Hidden Layers. Recurrent Networks apply the results of Hidden and / or Output Nodes back to previous layers as input. The Transformer Architecture, used for the networks that implement large language models like ChatGPT, are recurrent with multiple hidden layers, and implement some complex encoding and decoding.
Now that we have a neural network, how do we get it to do what we want it to do? What about the training?
Let’s go back to the weights on the connections between nodes. These weights comprise the majority of the neural network parameters mentioned earlier.
Neural network training is the search for a set of parameter values that solves the problem.
This applies to the training of any optimization problem. There’s a good reason that the first course in the UCLA graduate Artificial Intelligence sequence was “Problem Solving and Search.”
Most machine learning applications start with randomly set parameters values. Not surprisingly, these applications don’t perform very well at first. The object is to use training algorithms to find a set of parameter values that performs better. This is also an active research area. Lists of training algorithms, their details, and the scenarios for which they are best applied are readily available. But most use the same underlying principles, and despite often having impressive-sounding names, the basic concept can be easily visualized.
Imagine you want to find the point of highest elevation in the county, but you can only see a short distance in each direction and the area is too vast to exhaustively search. So, you pick a random place to begin and start walking in a direction that takes you up. You keep climbing higher and higher until you reach a point where the ground slopes down in every direction. You’ve found the highest point from where you started. This is called a local maximum. You don’t know, though, whether that’s the highest point in the whole county, the global maximum. You now have a couple of choices. You can remember this place and start over again somewhere else and see if you can find a higher point. Or, you can enlist the help of a bunch of friends and have each of them do the same exercise, competing to see who finds the highest point.
In general, you can’t be sure that you’ve found the global maximum without considering every point. You and your friends searched a three-dimensional space. As you keep adding dimensions … think billions of neural network parameters … you have to be content with finding a solution that’s good enough, and decide how much you want to invest to continue to look for better.
Now we can return to the question of how training works. The answer is the same today as it was back in the 1980s:
Training a neural network is accomplished by evaluating its results and adjusting its parameters in a way that reinforces correct answers and penalizes incorrect answers.
This process begins with the Output Nodes and the parameters are adjusted from right to left in a process called backpropagation. It involves lots of fancy math, but the most common training algorithms have already been implemented for you in analytics tools.
That’s it. Well, maybe that’s not all of it. There’s a whole bunch of nuances (aren’t there always), but you get the gist.
You are now ready for your Final Exam. The diagram below shows the Transformer Architecture which is at the heart of generative models like ChatGPT. It comes from the paper that launched this era of large language models, Attention is All You Need by Vaswani et al.
It’s very impressive looking, and it’s an impressive piece of research. So many arrows and fancy labels like “Softmax” and “Masked Multi-Head Attention,” but zoom out a little. It starts with Inputs (one of the inputs is confusingly labeled “Outputs” but that refers to taking the previously generated output and applying it back to the model as input) which are encoded into Input Nodes which are then passed to different sets of Hidden Nodes which ultimately produce an Output. Same song, different verse.
In generative language applications, the output looks like sentences and paragraphs, but it’s actually just a repeated sequence of “what is the most likely next word” given the input prompt and the words it has produced already. It doesn’t “know anything” about the Gettysburg Address or peach cobbler.
Congratulations! You now have a basic conceptual understanding of neural networks, and how simple concepts can be assembled to form the internals of the new large language models. You should also be able to begin to discern real risks from the hype. But I’ll talk more about that in a future article.


