Listen to this article:
In the beginning there was language, and from language evolved grammar, and grammar begat sentence diagrams. It seems like the portion of the population that diagrammed sentences in school is like the portion of the population who are Korean War veterans. They’re still around but their numbers are dwindling. I’m not sure that anybody born later than the 1960s has ever done it. It’s too bad. It’s a great tool for understanding how language works. But it’s like diet and exercise. We’re always loathe to do things that are good for us.
Sentence diagrams illustrate the architecture of a sentence and how the different parts fit together. The school district where I grew up provided textbooks for each class. The old textbooks were stored on shelves in a closet in the back of the classroom. Those shelves were filled with books from the 40s and 50s. Some of you may remember them. The brittle, slightly yellowed pages. The musty smell of a book that hasn’t seen the light of day in decades. The names and years of former students that used the book printed inside the front cover. Book covers made of paper grocery bags. (One book I had sported a 1960s-era Civil Defense cover that described what to do if you saw the flash of an atomic bomb.) But I digress.
An old grammar book I once found went into diagramming sentences in great detail. I asked my parents about if they remembered it from when they were in school. They did. Subject and verb on the main line. Adjectives and adverbs connected to the words they modify. Subordinate clauses branching off with their own diagrams.
Here’s the diagram for the sentence, “The quick brown fox jumped over the lazy dog.”
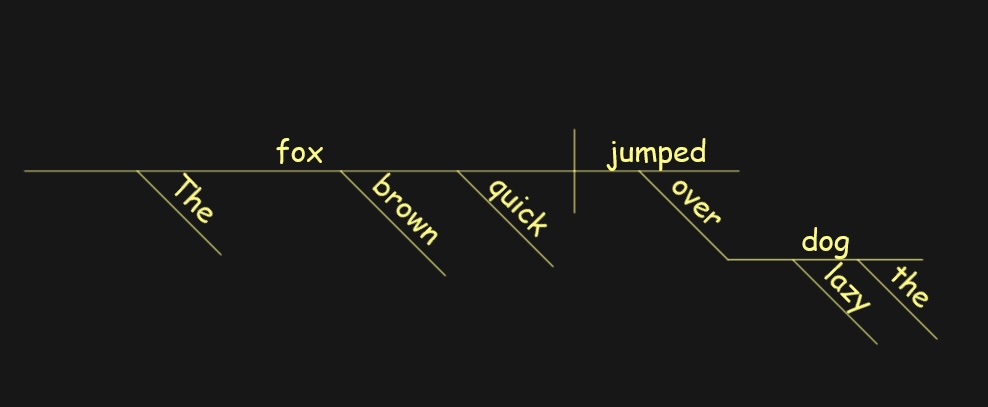
It’s not surprising, then, that researchers trying to figure out how to get computers to understand natural language back in the 1950s and 1960s started with structural approaches. Well, sort of. They didn’t diagram sentences in the computer, but they did use formal grammars and parsing algorithms. The objective was still to represent sentence structure in a way that captures how the parts relate.
This approach worked well for creating a representation for the sentence, but the next challenge was figuring out what to do with it. The representation lacked context. It lacked a fundamental understanding of the world. And it lacked an understanding of the subtleties of the language itself.
In 1969, Roger Schank introduced Conceptual Dependency theory. It was refined through the 1970s, and was still the primary Natural Language Processing methodology being taught when I started graduate school in the 1980s. I still have the textbooks, Inside Computer Understanding and Scripts Plans Goals and Understanding. The idea was that meaning could be expressed in a conceptual representation that avoided ambiguity and differences between languages.
The focus was on the actions or events, where “every event has an actor, an action performed by that actor, an object that the action is performed upon, and a direction in which that action is oriented.” All actions can be represented with about a dozen primitive concepts. The one that has always stuck in my memory is INGEST because it represents both eat and breathe. You can physically transfer (PTRANS), abstractly transfer (ATRANS), and mentally transfer (MTRANS). MBUILD represents constructing or combining thoughts to create new information. The rest are pretty self-explanatory.
ATRANS PTRANS PROPEL MOVE GRASP INGEST
EXPEL MTRANS MBUILD SPEAK ATTEND
To provide the context, scripts were developed to encode domain knowledge. The most common example is the restaurant script that encodes information about reservations, seating, menus, ordering, eating, paying, and leaving. In my Natural Language Processing class I wrote a script that described the interactions between an air traffic controller and a pilot. And in that assignment lies the problem with this approach: a very large amount of script development effort for a very small amount of domain coverage.
Nevertheless, Conceptual Dependency Theory was revolutionary for its time. It was a language-independent coding model that captured meaning and intention in addition to syntax. It was a significant advance in encoding, and a first step in capturing context.
Unfortunately, at about the same time I was learning it, manual knowledge encoding was falling out of favor, replaced by statistical and machine learning methods. I referenced some of those methods in the background research I did for my Masters Thesis. I wanted to encode context within a neural network, and used a recurrent feedback loop. This is very similar to the Transformer Architecture that is foundational to current Large Language Models. I didn’t come up with the idea, though. Recurrent network architectures had been explored a few years earlier by Michael Jordan, Jeffrey Elman, and others. I was just building on them.
I used the following example in my Thesis: Consider the word ball in the sentence, “The pitcher had a ball.” The word in isolation could mean a round object, a party, a pitch out of the strike zone, or a pleasant experience. Placing the word in the context of the sentence, “The pitcher had a ball” eliminates the second and third interpretations, but still leaves plausible the other two. Only with the context of the surrounding sentences can the word be fully disambiguated, as in, “The players were assembled. The pitcher had a ball. The game was ready to begin.” The word would have had a different meaning in, “The championship celebration lasted far into the night. The pitcher had a ball. So did the catcher, but the shortstop got sick.” It’s only when we add the context that we can disambiguate.
As computing power increased over the next few decades, these methods progressed incrementally. Machine learning and deep neural networks. Statistical patterns of meaning. Feature engineering. And later distributed representations for words and sequences. Understanding improved and context improved.
Recently, the Transformer Model has revolutionized Large Language Model development. These models are general purpose and context aware. And trained on massive amounts of data. The key insight of “predicting the next word” is embarrassingly simple.
Interestingly, as understanding and context have improved, the internal representations of language have diverged farther and farther from the grammar models. We’ve ended up going the opposite direction from where we started. The less structured the internal representations, the better the network performs on the task. But those less structured representations require a whole lot of “hardware,” a.k.a. lots of nodes and lots of parameters. We didn’t have the computing power 30 years ago to make that happen.
And it’s closer to how the brain works. Lots and lots of neurons. I don’t think there’s a grammatical sentence parser in the brain. Or a Conceptual Dependency diagram. We are shown examples and we learn examples. We practice. Reinforce. Correct. Our understanding is messy.
I expect the coming years to be a period of rapid incremental improvement along this path, with the models improving in understanding, reasoning, contextual awareness, factual accuracy, and safety. We may need to dust off the Turing Test again. It might not be long before you can’t tell whether you’re talking on the phone with a person or a computer.
Sentence diagram generated by Sentence Diagrammer for Windows.


