Listen to this article:
Last week was the DGIQ-EDW conference in San Diego. It’s one of the leading industry conferences for data professionals, focusing on practical enterprise topics like AI governance, data architecture, stewardship, and organizational strategy. If you’ve never been I very highly recommend it. My agenda included teaching a Data Products workshop, watching several interesting presentations, speaking with vendors both new and old, and catching up with conference friends that I only get to see once or twice a year.
I filled half of a spiral pad with notes and ideas. It took me the better part of a day to go back through them and digest everything.
Many of the sessions were recorded and will be available through DATAVERSITY. Rock Bottom Data Feed podcast listeners can get a discount at dataversity.net. There was so much to see and hear, but I will coalesce my conference takeaways into the three that stood out the most to me.
1. Data may be getting more executive attention than we think. We need to recognize it, extend ourselves into the business, and be prepared when they express interest.
One of the general session segments was a “fireside chat” with Donna Burbank. She attended the World Economic Forum in Davos, Switzerland earlier this year and shared her experience and observations. Most significant were the widespread conversations among leadership, both corporate and government, around the need for Data Governance and Data Quality. It was particularly shocking since those of us in the data profession take it as a given that leadership doesn’t care about data. Perhaps it shouldn’t have been shocking. What they’re really interested in is AI, but recognize that successful AI requires Data Governance and Data Quality. Of course, awareness isn’t the same thing as action, but it’s a necessary first step.
Donna made the point that data professionals have a great opportunity to participate in these conversations, and to drive the activities that we’ve been trying for so long to move forward. Right now, though, leadership is largely educating each other. We need to fill in those blanks. Let’s not overwhelm them with process and jargon, but reach out to business professionals where they are, speaking first in their language.
2. Data Products are becoming a recognized mainstream prerequisite for successful AI.
I might be biased here, but I am seeing more and more companies adopt Data Products to support their Data Governance and Data Quality initiatives to in turn support their AI initiatives. AI is the motivator, the accelerator, and the stress test. After this week, I’m even more convinced that Data Products are necessary for enterprise data teams to support scalable AI.
My Data Products class had twice as many attendees than last year if that’s any indication. The week before the conference I sent out a short survey to those registered for the class so that I could tailor the session to their priorities and highlight common challenges. Forty percent responded. Here are a few of the results:
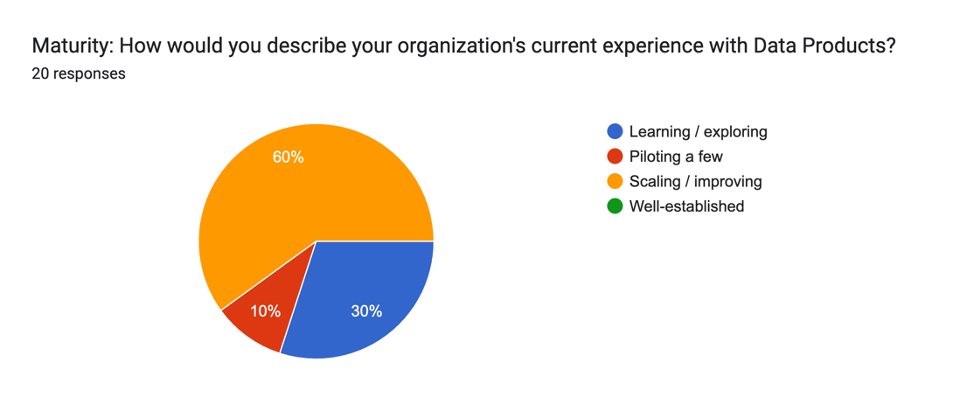
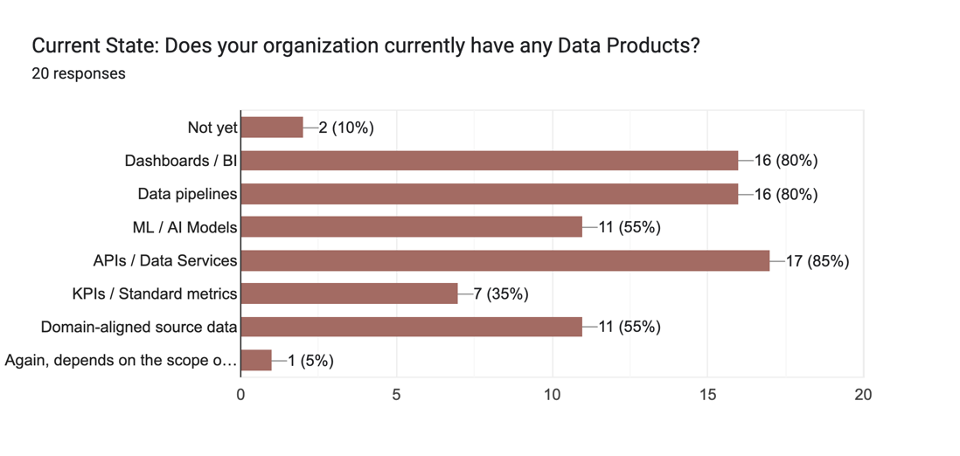
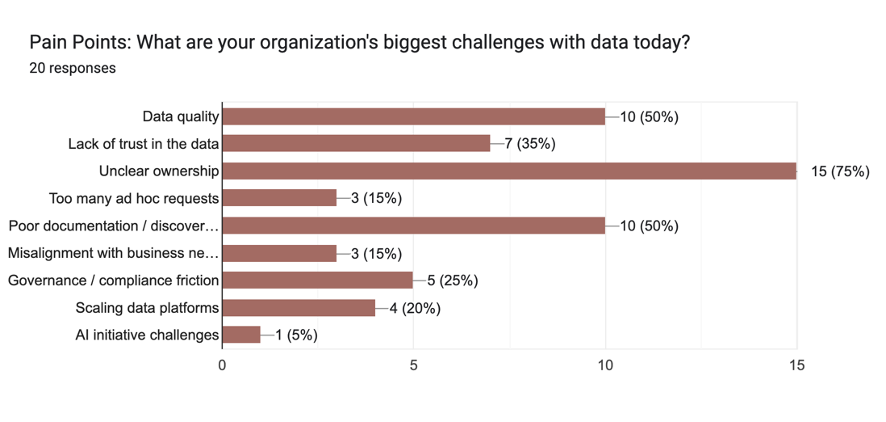
Seventy percent of the respondents had already deployed Data Products, with the overwhelming majority having more than a few. This result needs to be taken with a grain of salt, though, since we were not all using the same definition of Data Product. If you’ve read any of my Data Product articles, you know that the “product” in Data Product is reliability. Without the curation, support, monitoring, and maintenance you might have a nice data asset, but you don’t have a Data Product. The challenges that most of the respondents were having, specifically ownership, Data Quality, and documentation, reflected this disconnect.
The role of Data Contracts in Data Product implementation is also coming to the forefront. We’ve seen some success with the productionization of Data Profiling practices, but with scant process support in most companies, widespread adoption has been elusive. Now, a large part of Data Governance can be automated.
Data Contracts are the foundation of Data Product and Data Governance automation.
Furthermore, AI can be used to create metadata as well as to evaluate metadata quality. It’s much easier for Data Owners and Data Stewards to edit definitions than it is to compose them. AI leverages Data Products, and Data Products are increasingly leveraging AI.
3. Data Governance Metamorphosis
This is the one that I find most exciting. I’ll probably write more about this in the coming weeks and months. I’ve written before (here and here) about how AI could be leveraged for Information Management and Data Governance. It’s happening. Right now. Data Governance disruption has started. Momentum is building.
This is not Data Governance evolution. It’s a renaissance and a transformation.
You might say Data Governance is in the chrysalis phase between the caterpillar it’s been for the last thirty plus years and the butterfly it will become in the next five. Given the pace of change, it might not even be that long.
AI is exposing data deficiencies. Most corporate data estates are like houses built on the sand. Everything appears OK until the storm comes. Then we discover that maybe we don’t have the firmest foundation.
AI is also upending Data Governance, and that’s most clearly seen in the changing face of tools. Many are using AI to implement existing processes faster. That’s the old way with Windows explorer folders and forms with check boxes and radio buttons and text fields, sprinkling AI around the edges of an approach to Data Governance that’s not been working.
I’m not sure that anybody really wants to work with metadata. Not even data people. Maybe there’s a few, I suppose. But, why did we ever think that we could get the developers and businessfolks to do it? Especially when we gave them Windows explorer folders and forms with check boxes and radio buttons and text fields. Yes, those forms and workflows are necessary, but not for most people.
Data Governance and Metadata collection must be maximally automated and conversational.
With AI we have the opportunity to automate formerly manual processes and to interact with users, developers, Data Owners, Data Stewards, and even leadership in the way that they want to interact. Conversationally. Both data entry and retrieval.
The tools are starting to support that interaction. One of the exhibiting companies, Elementary, said it best: “We are going from managing data to managing agents.” I would add that we’re going from managing metadata to managing agents.
Everyone is concerned about AI replacing people, and enterprise data teams are no exception.
It is critical for leadership to recognize that AI should not be used to replace data professionals, but rather to allow those data professionals to do what they should have been doing all along but lacked the time.
Leave the other stuff to AI. A quick story. It’s ancient history. It’s been told many times at conferences and at meetings, but it illustrates the point perfectly.
Our data warehouse was running on Informix. It was state-of-the-art, high-capacity, and high-performance for the time. It achieved that high performance by optimizing large table data access by explicitly distributing data to specific disk locations. The DBAs spent a lot of time analyzing the data coming into the system and evaluating its utilization patterns. The result was DDL that ran more than 30 pages for a single table, most of it being an if-then-else ladder that determined data placement on disk. It all worked well and performed well.
As we approached the system’s scalability limit, the decision was made to migrate to Teradata. On that platform, even back in the late 1990s, disk space management was handled automatically. This concerned the DBAs. After all, they had been the center of the data warehouse universe. They had to be deeply involved any time a new table was created or an existing table was expanded. Now, the overwhelming majority of their work had been automated.
Does this sound familiar? Like something that’s happening now?
I was managing the group at the time and met with the DBAs. I pointed out that, yes, most of what they were currently doing would no longer be needed. But then I turned their attention to the long, long list of things that they said that they would like to do but couldn’t because they were spending all their time figuring out how to distribute data. Trifles like security. And performance. And user management. And optimization. Looking at it that way, they became much less concerned. Nobody really liked doing disk space management, and they were much happier doing the stuff that they wanted to do.
AI will be the same way. Many of the enterprise data teams’ current tasks will no longer need to be done (at least by them), allowing them the time to do those things that they said that they would like to do.
AI will free up the existing data teams to do those things that are most needed to support scalable AI.
AI will be integrated not only into Data Governance tools, but more importantly into the Data Governance processes.
Data Governance metamorphosis will not change what needs to be done, but rather the who, the where, and the how it will be done.
It will change the responsibilities, the organizational alignment, and the processes.
My final observation, at least for now, is that when it comes to applying AI to Information Management and Data Quality, everybody just seems to know what to do. This is fascinating to me. There weren’t armies of consultants or vendors. The typical cadence for a new product feature released at the annual conference is that it is announced the first year, discussed by a few early adopters the second year, and used more broadly the third year. Now, new features are released and consumed almost instantaneously. Companies just started finding use cases and moved forward themselves. In some cases, the market is leading the consultants and the vendors.
I’ve been through several “next big things” in data and analytics. AI has been the most exciting, but the prospect of AI enabling a Data Governance metamorphosis may be the most exciting yet.
Featured Image: Hectonichus, “Nymphalidae – Danaus plexippus Chrysalis.JPG,” CC BY-SA 3.0, via Wikimedia Commons.



{kind=link}